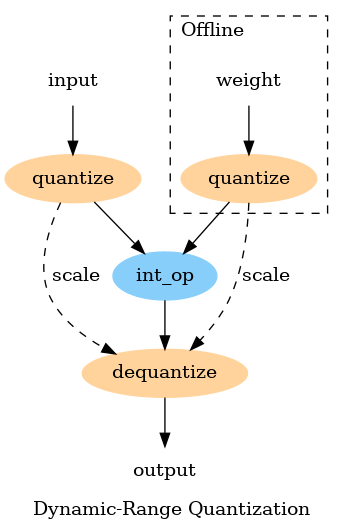
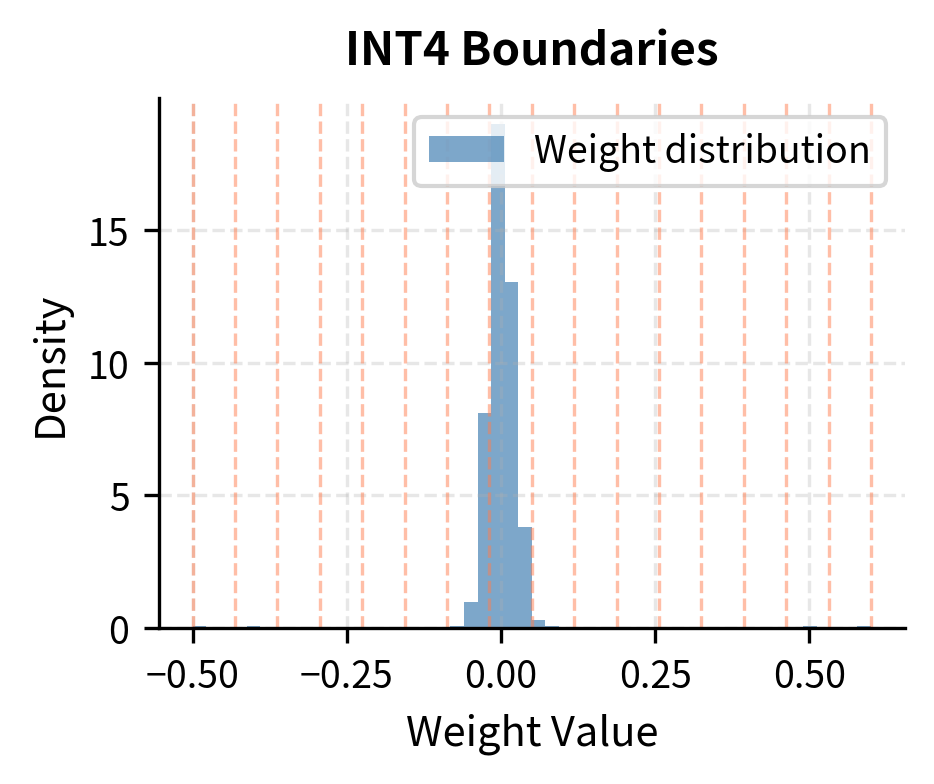
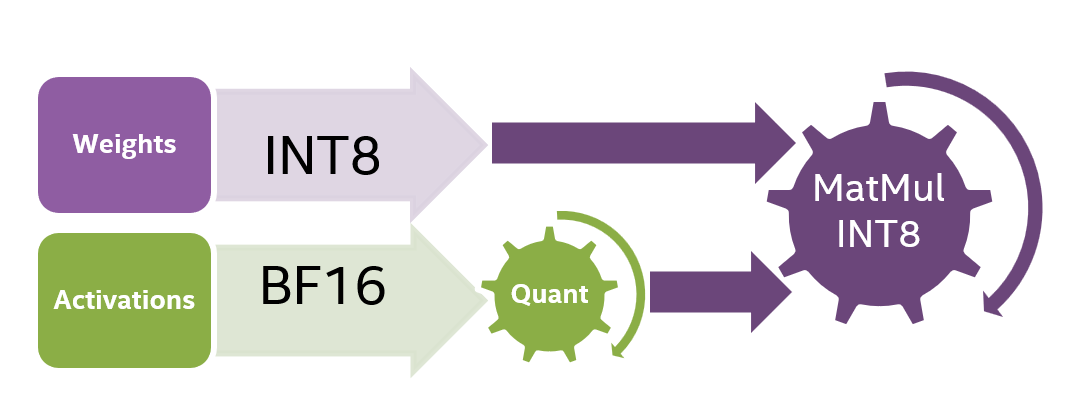
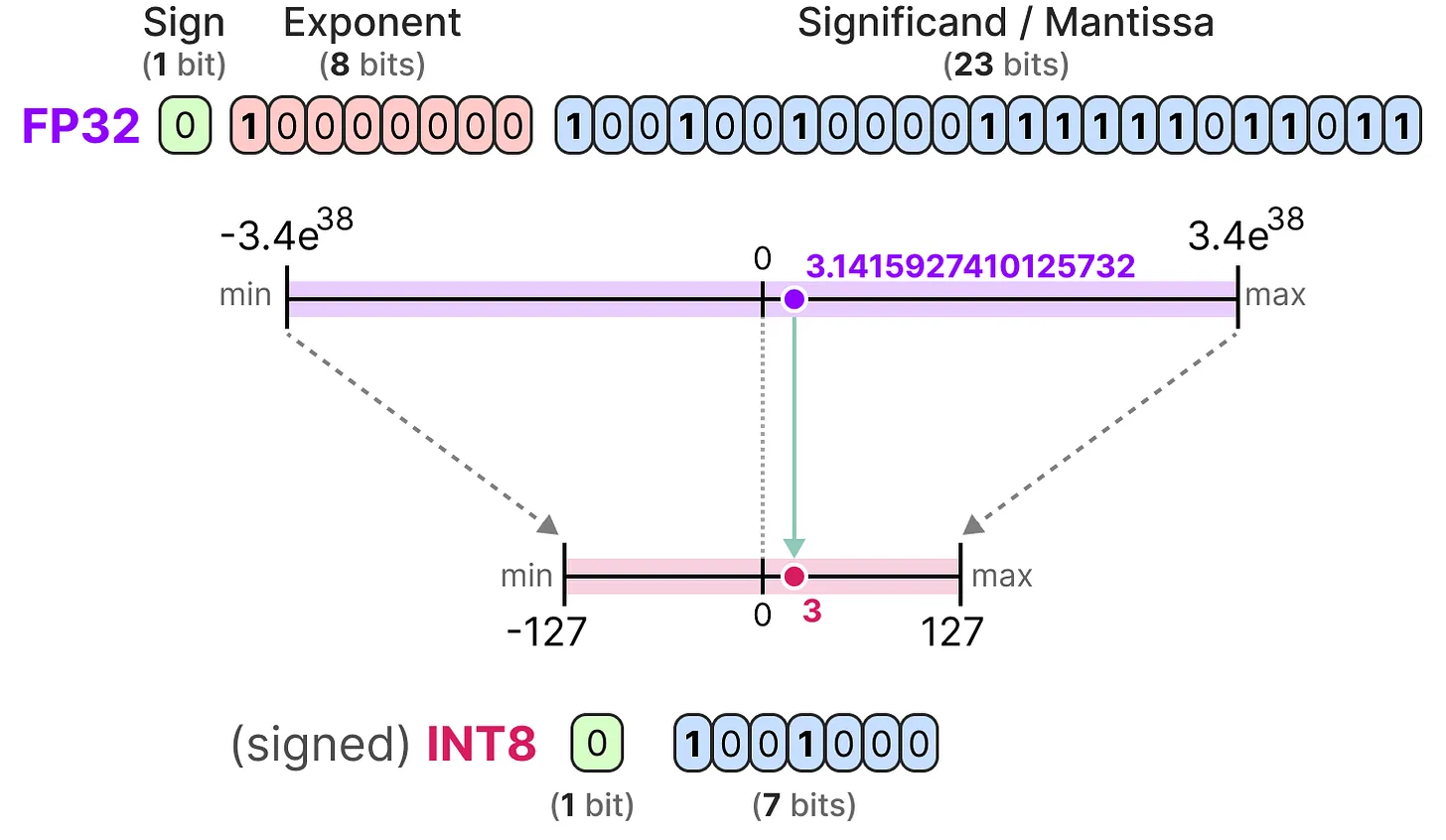
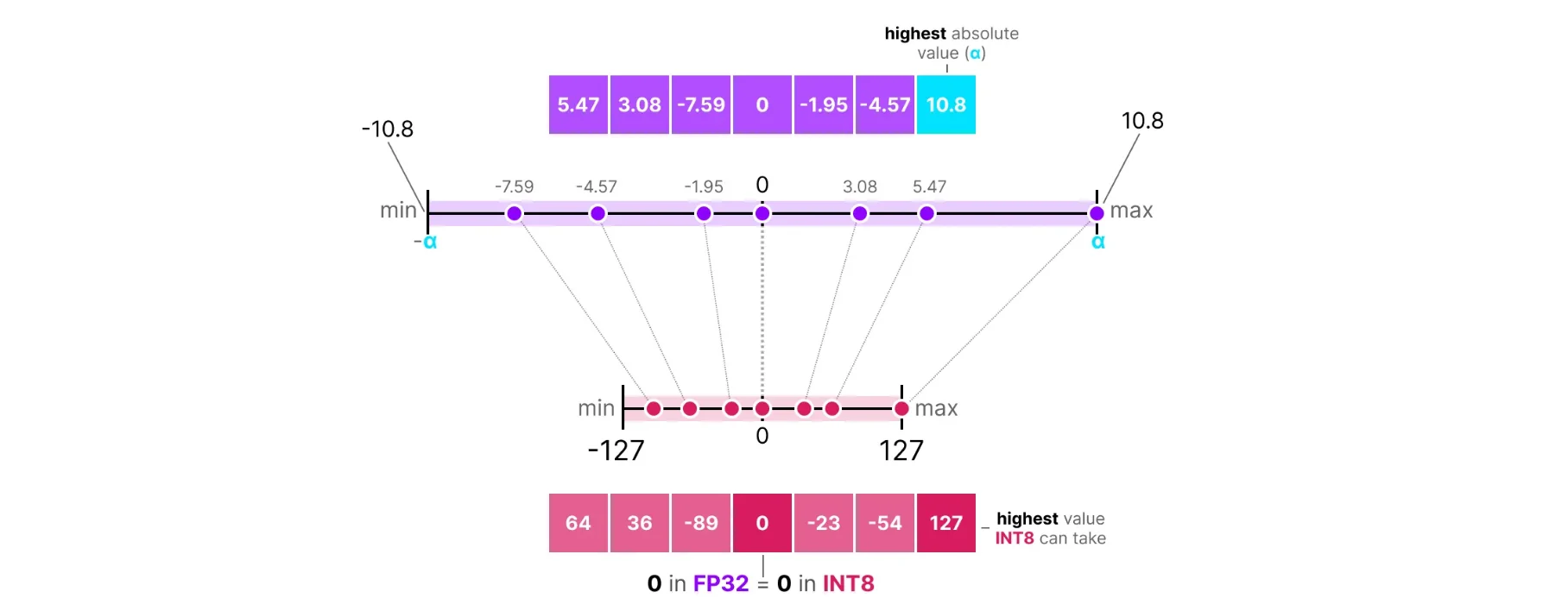
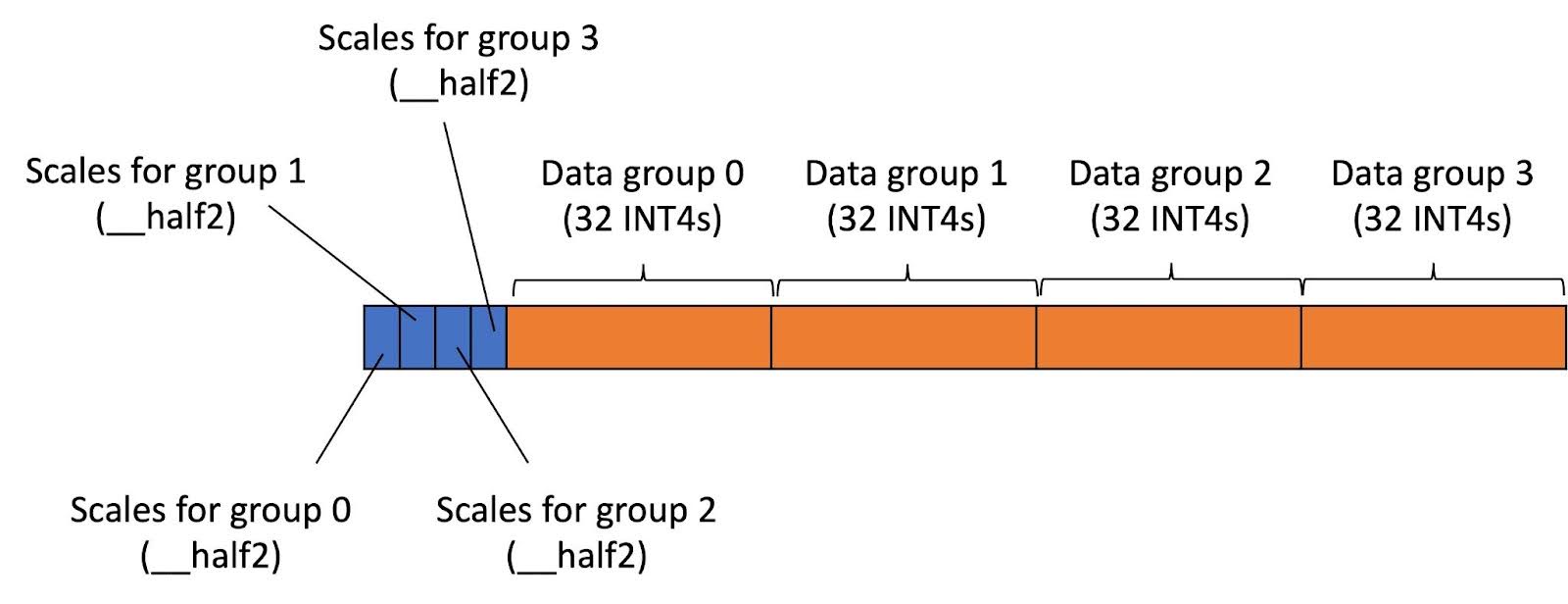
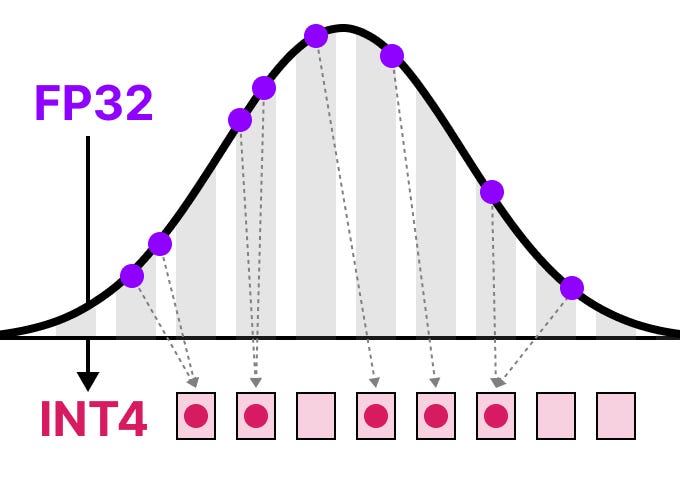
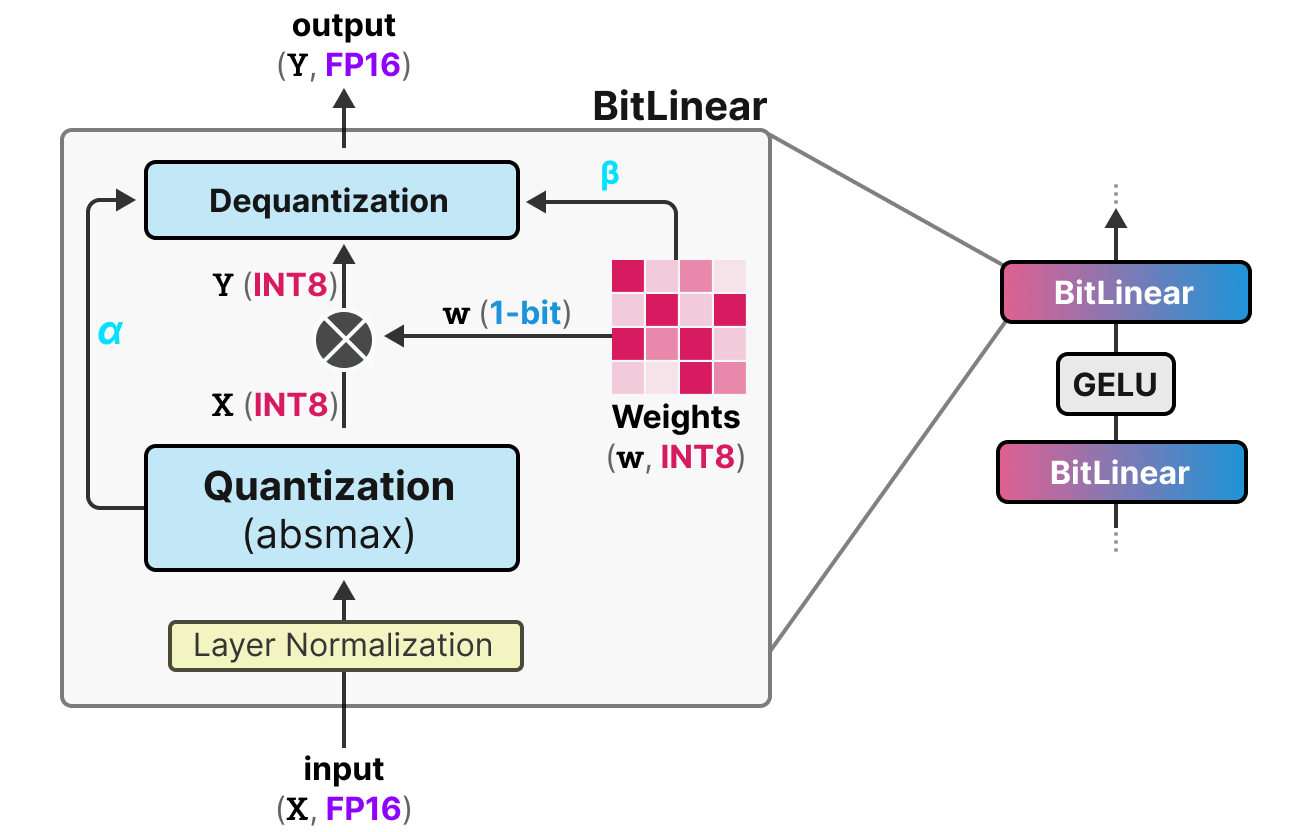
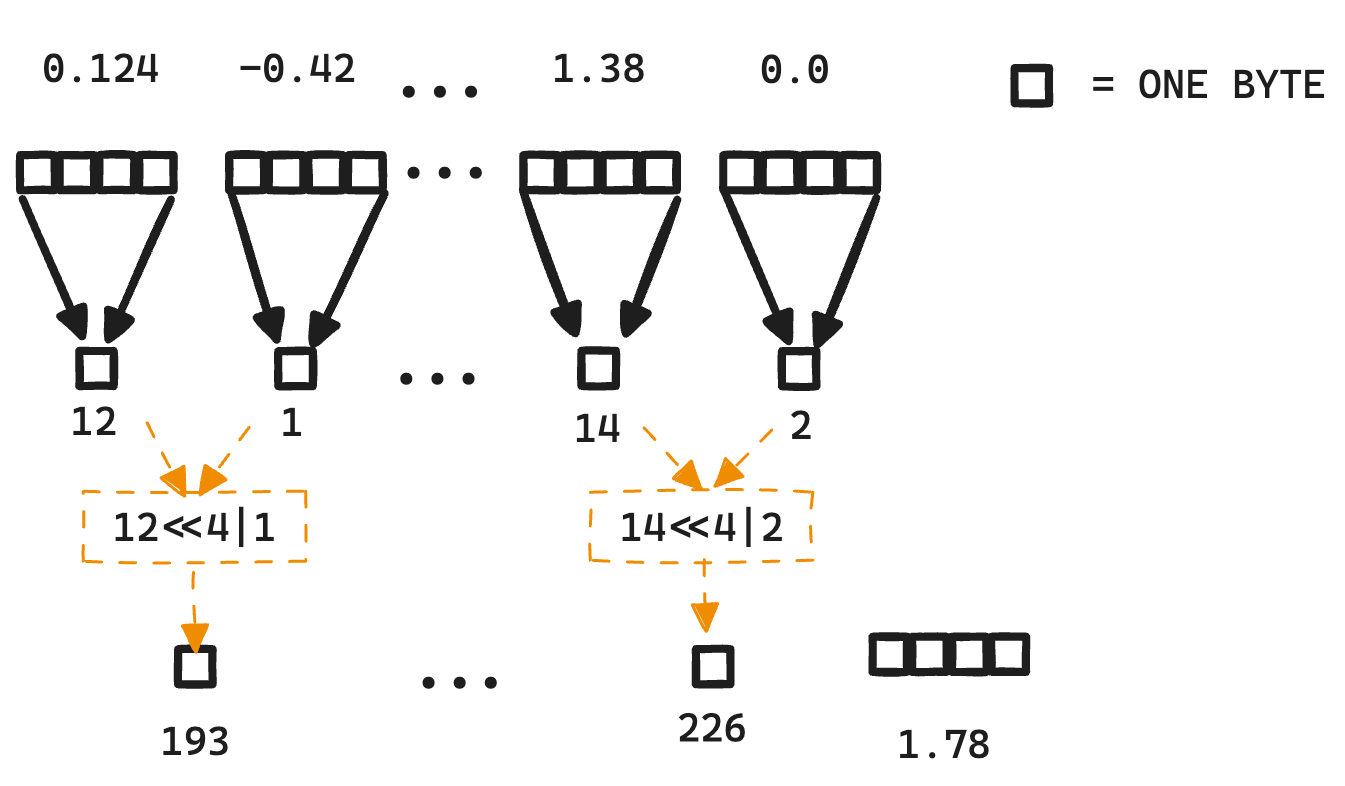
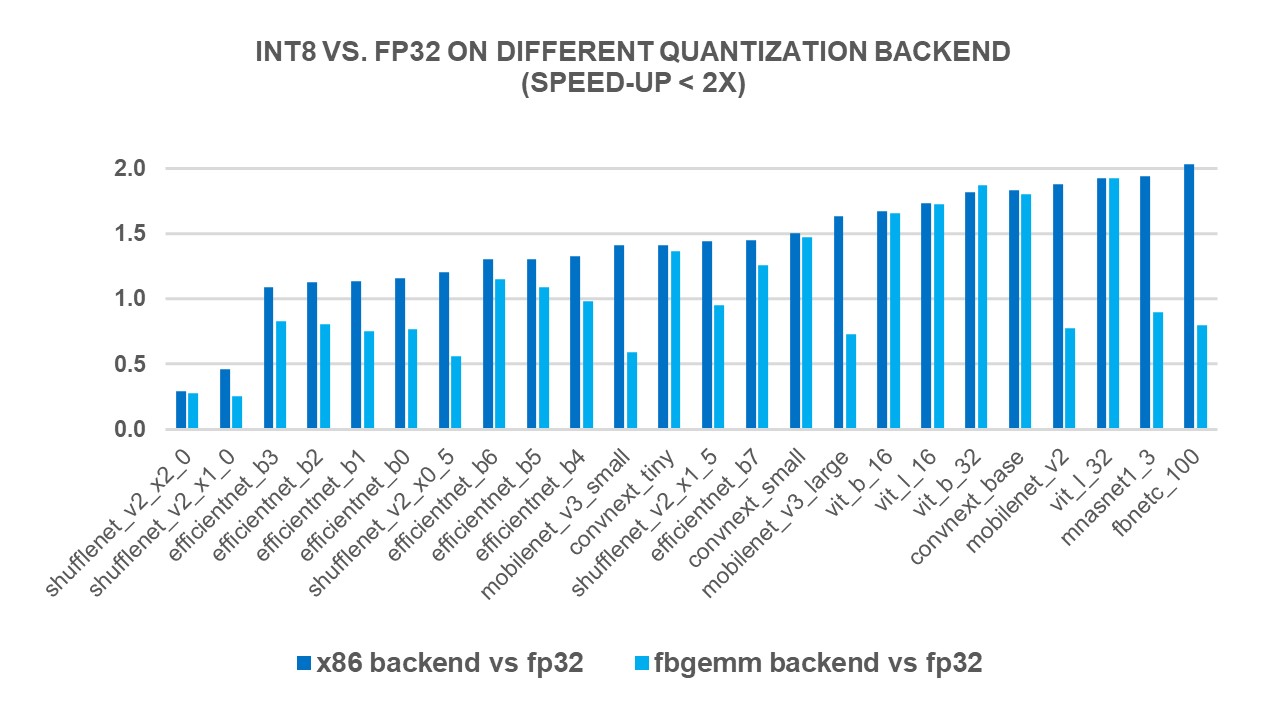
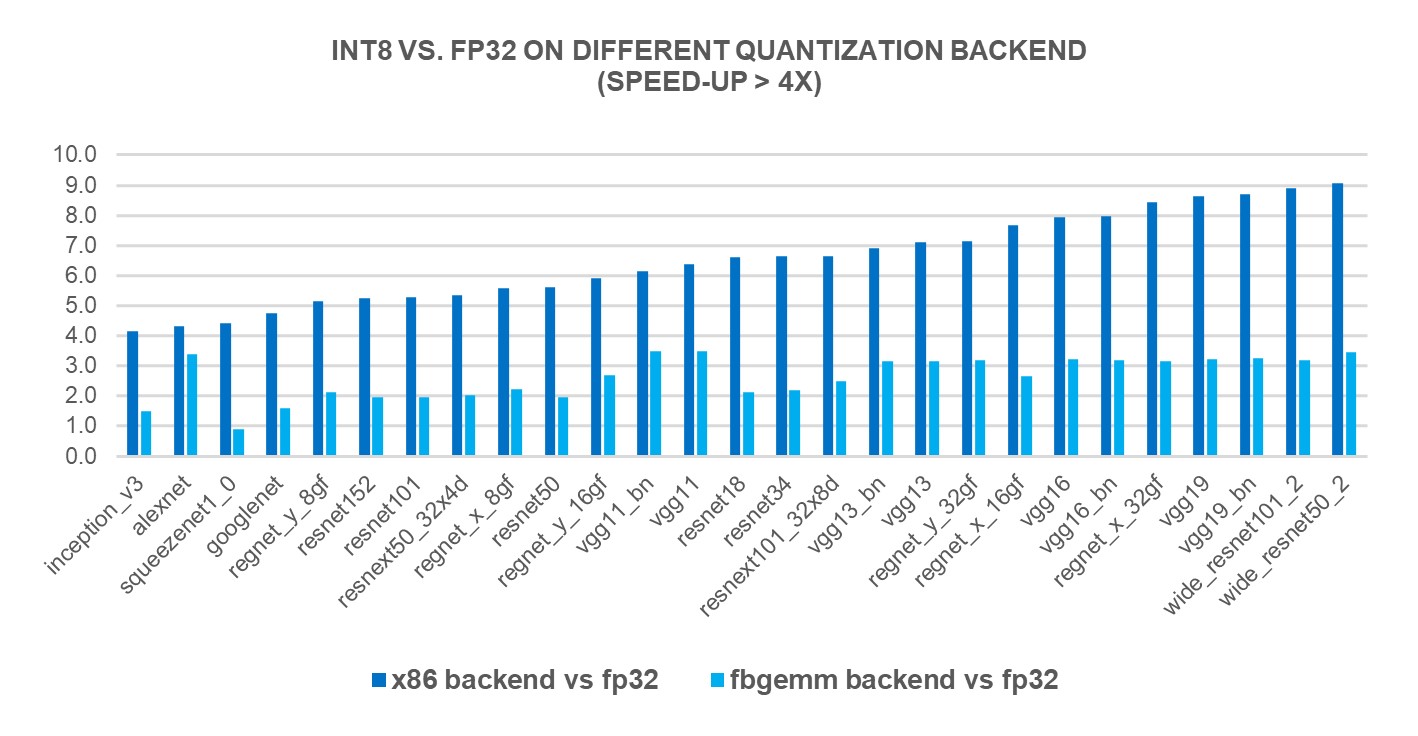
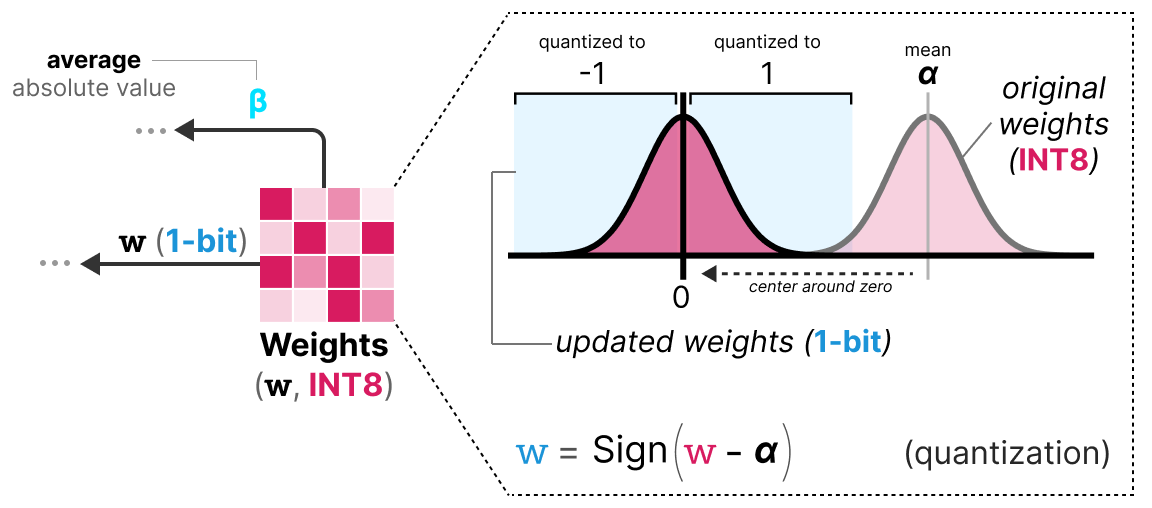
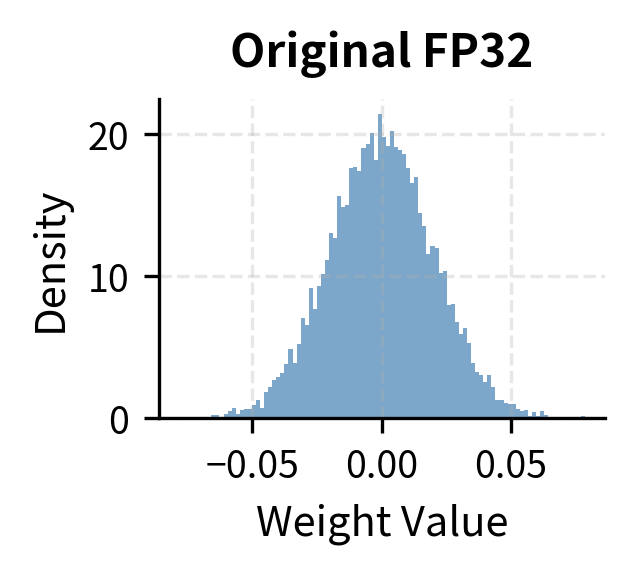
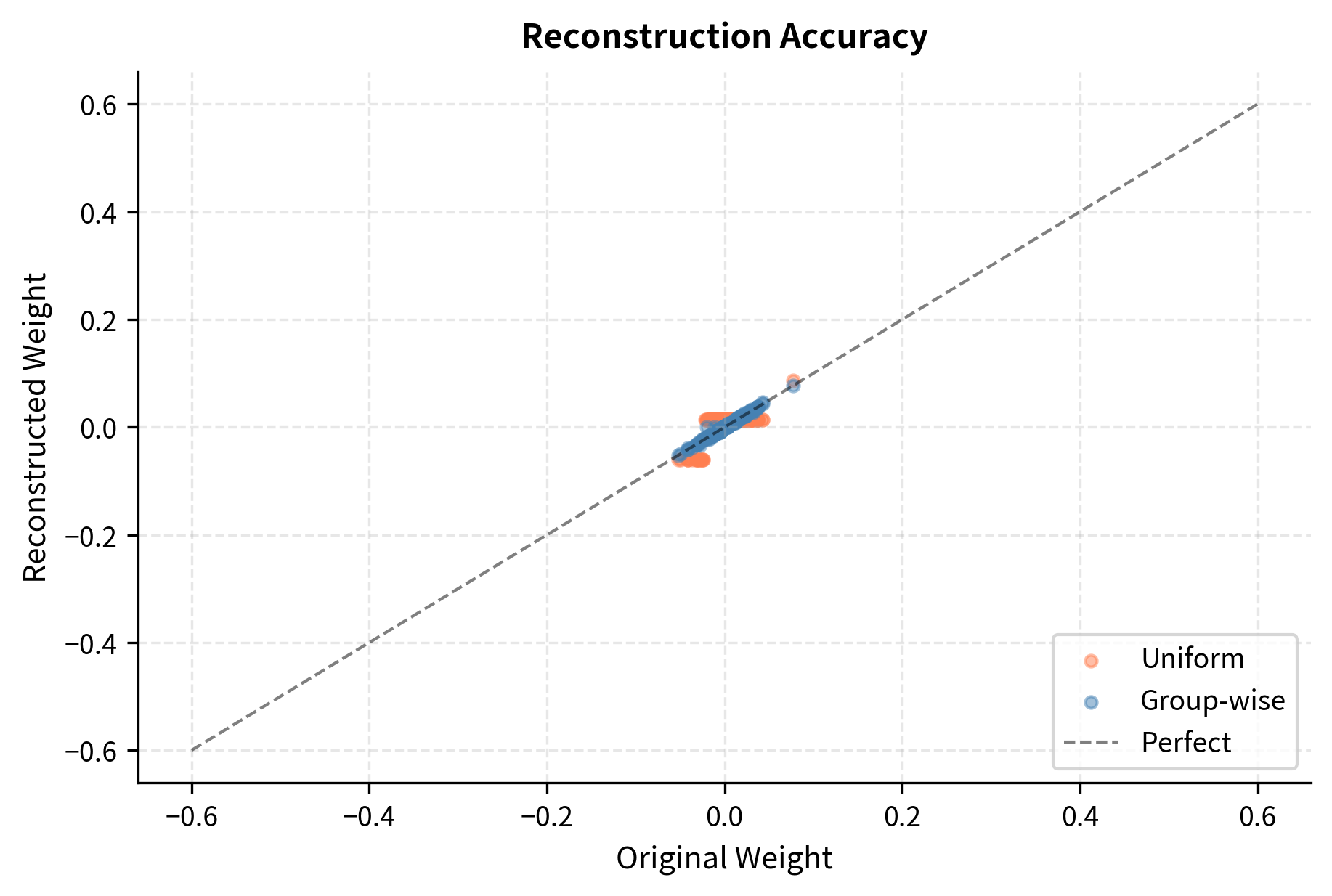
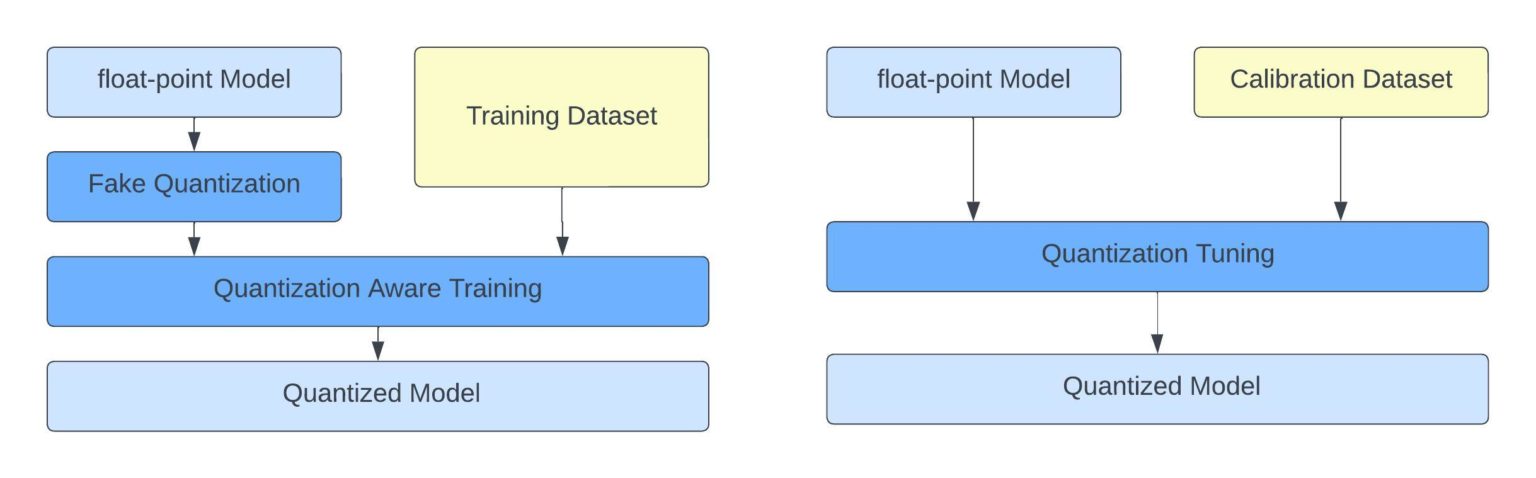
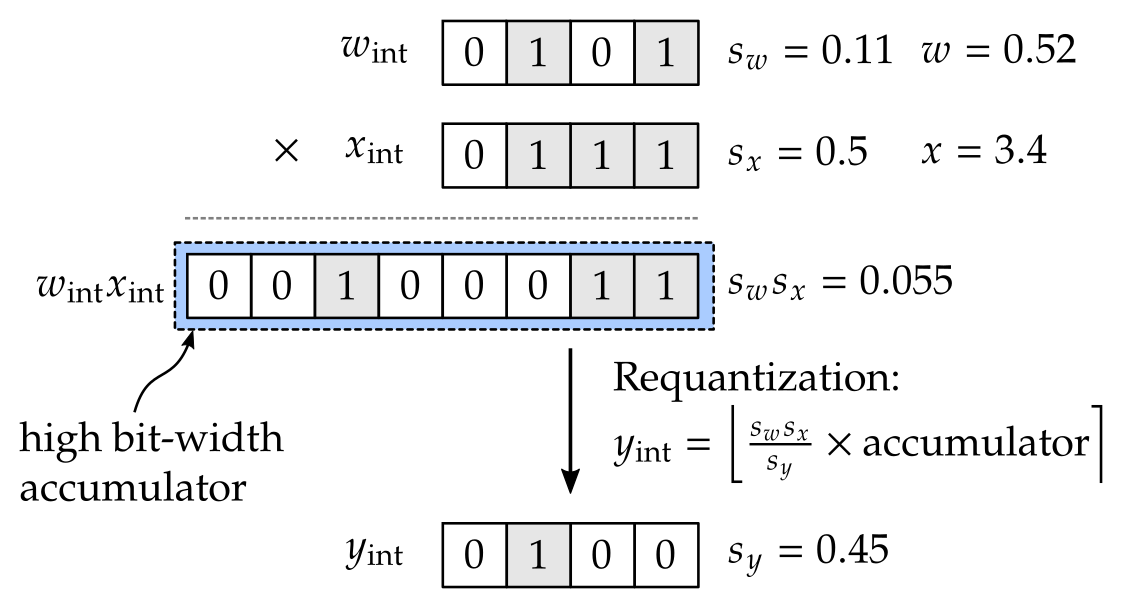
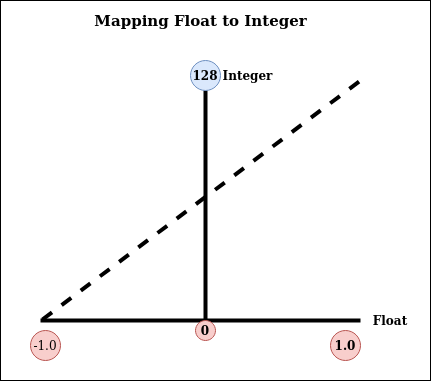
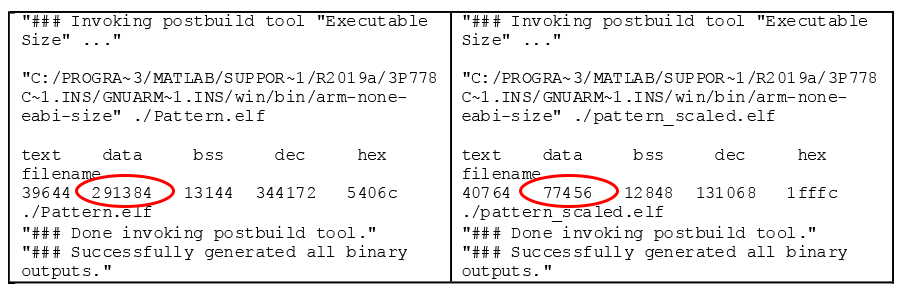
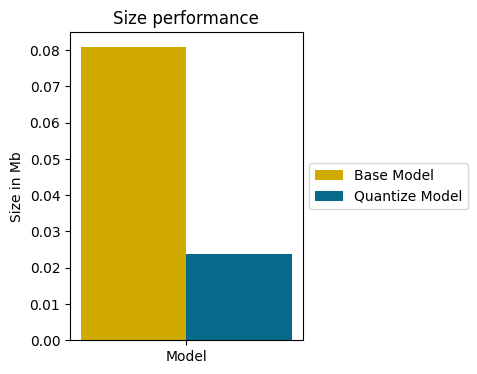
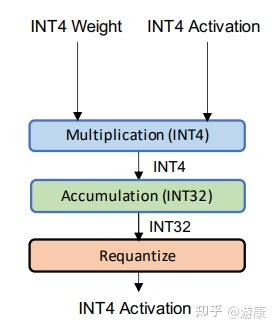
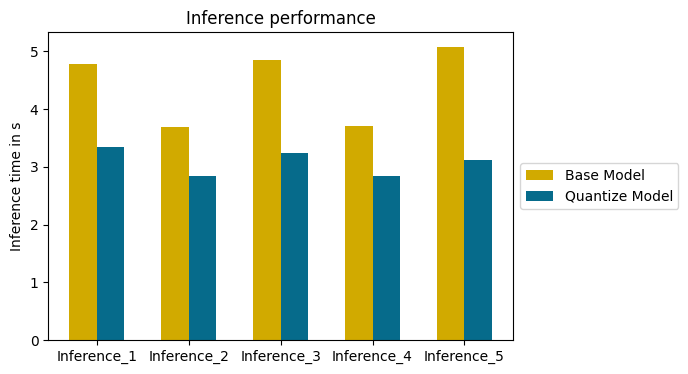
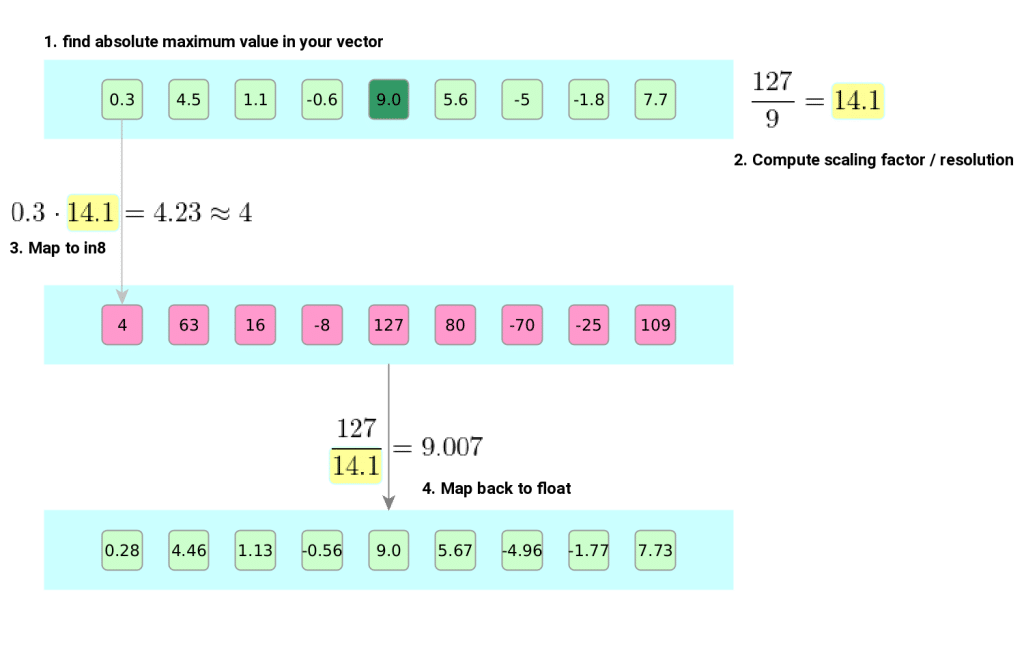
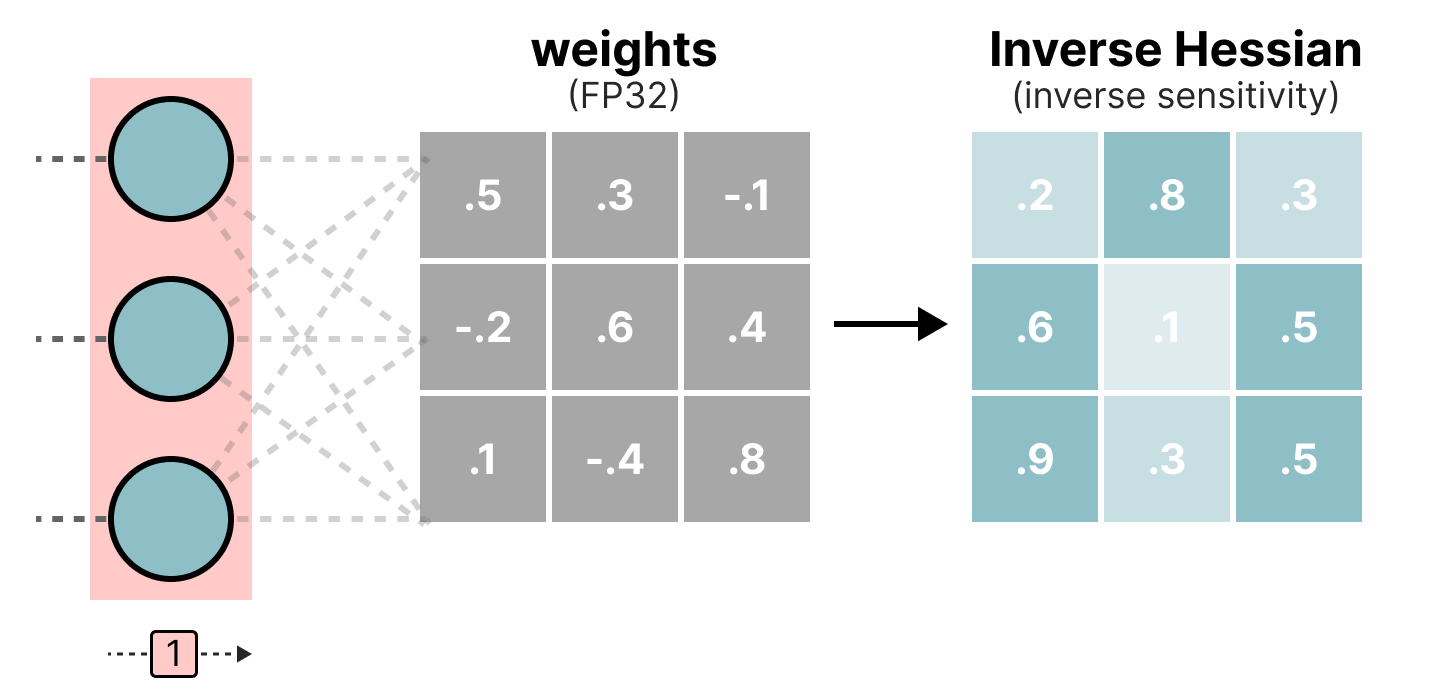
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
How to full int 8 quantize a yamnet model? · Issue #56313 · tensorflow ...
The INT quantization paradigm. | Download Scientific Diagram
INT vs FP Data Types for Quantization - by Benjamin Marie
How to Quantize Neural Networks with TensorFlow « Pete Warden's blog
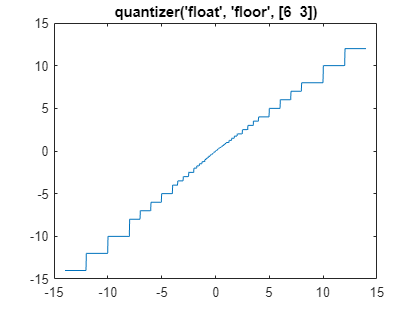
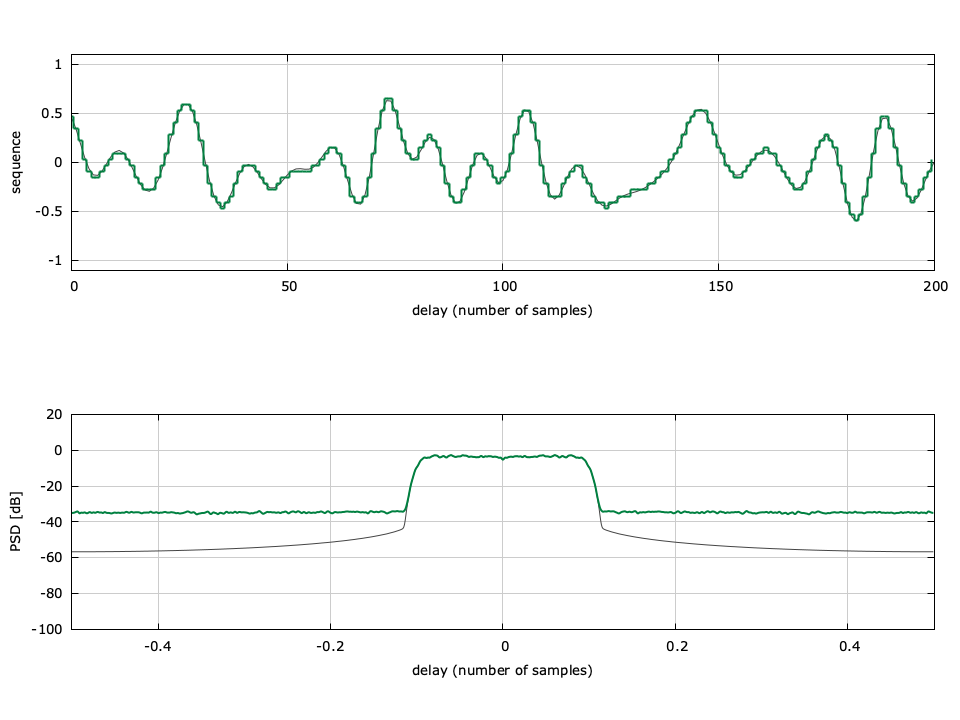
quantize - Quantize numeric data using quantizer object - MATLAB
QUANTIZE - DADiSP
The EASY Way to Quantize in FL Studio + (6 Tips) – Producer Society
4-bit LLM training and Primer on Precision, data types & Quantization
Quantization Overview — Guide to Core ML Tools
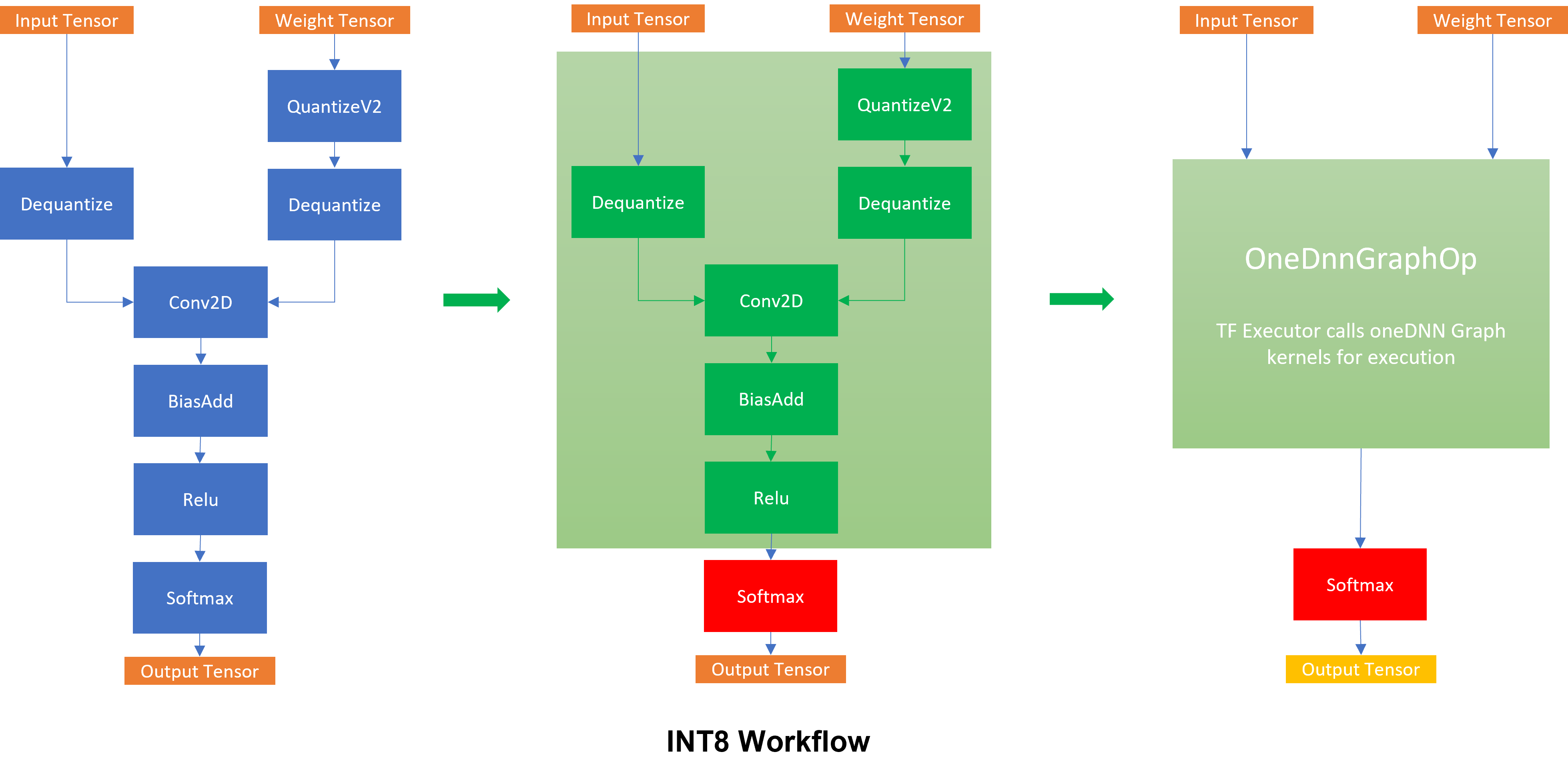
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
Floating-point Arithmetic for AI Inference: Hit or Miss? - Edge AI and ...
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
A Hands-On Walkthrough on Model Quantization - Medoid AI
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Quantization Basics — qwix documentation
Deep Learning INT8 Quantization - MATLAB & Simulink
INT4 Quantization: Group-wise Methods & NF4 Format for LLMs ...
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
Quantization — Deep Learning Course
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
INT4 Decoding GQA CUDA Optimizations for LLM Inference | PyTorch
Improving LLM Inference Latency on CPUs with Model Quantization ...
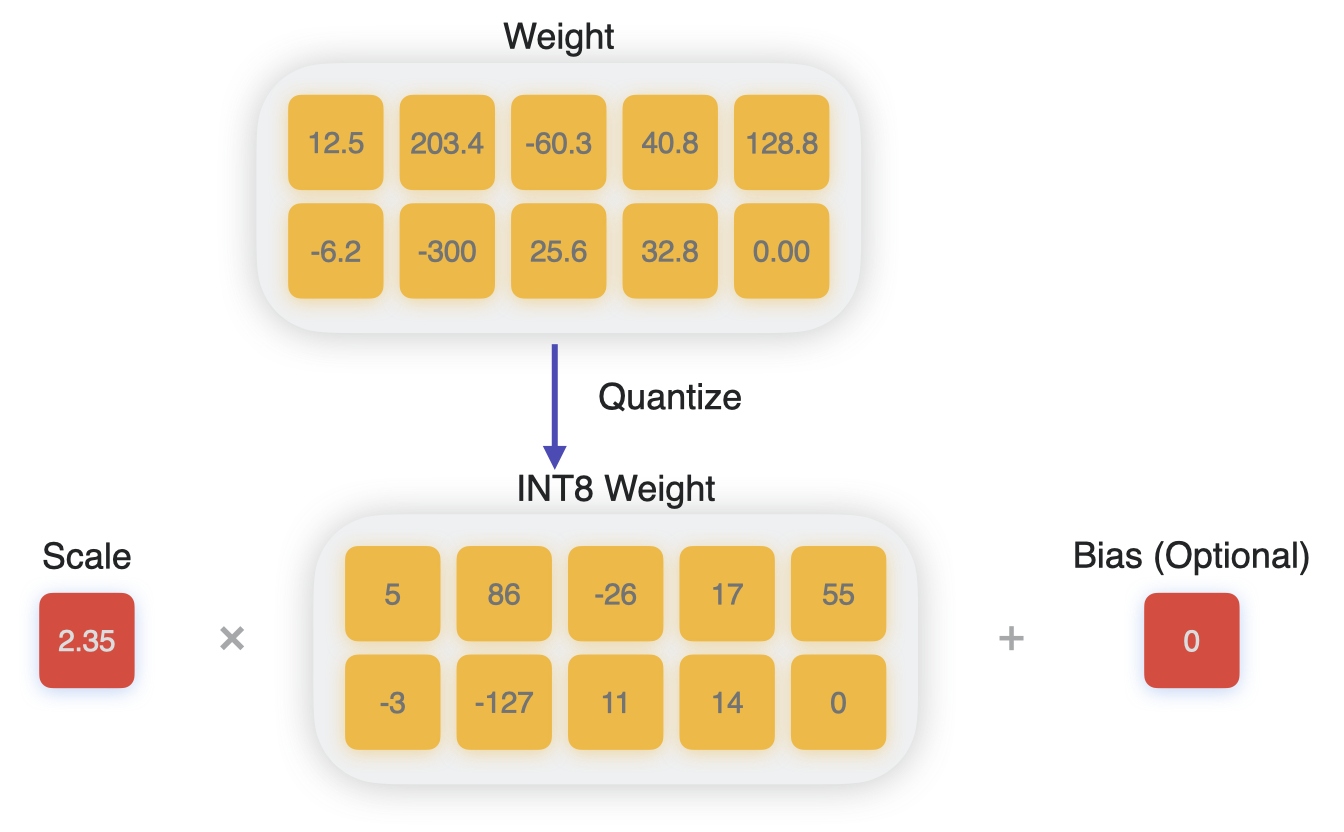
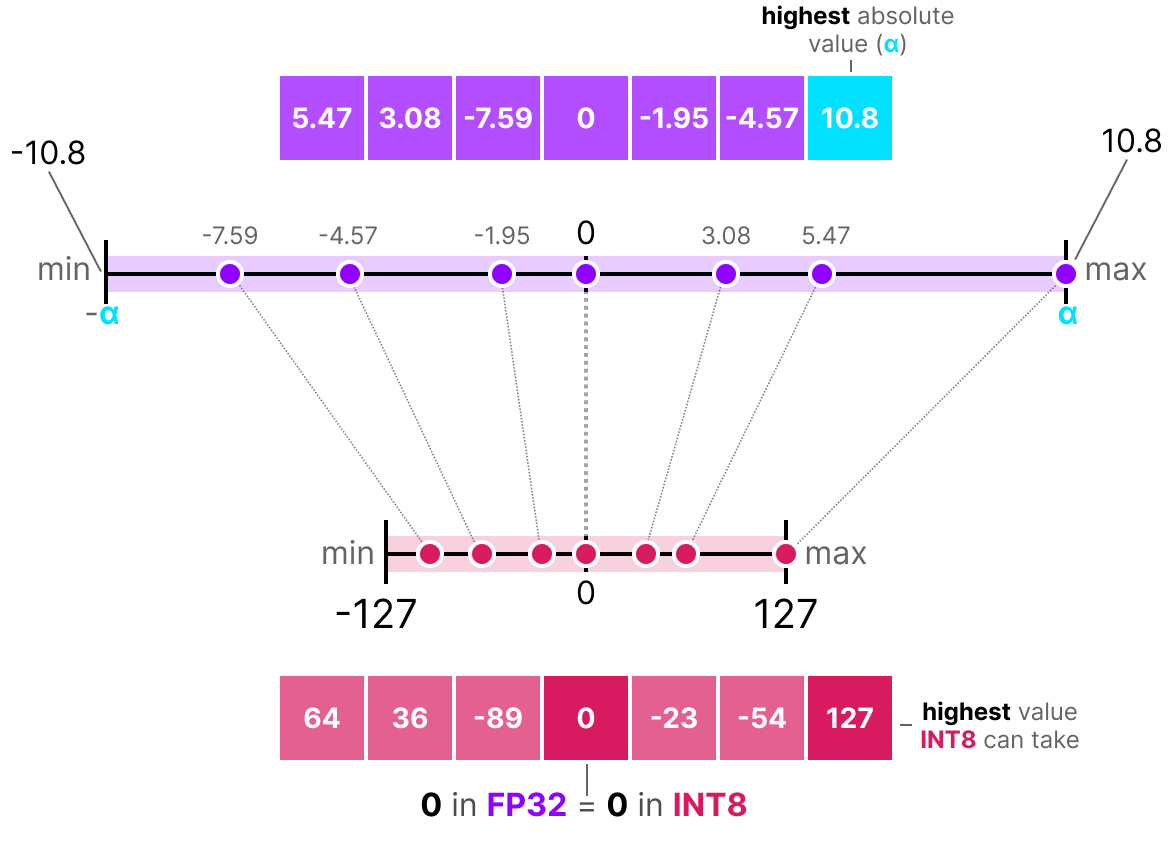
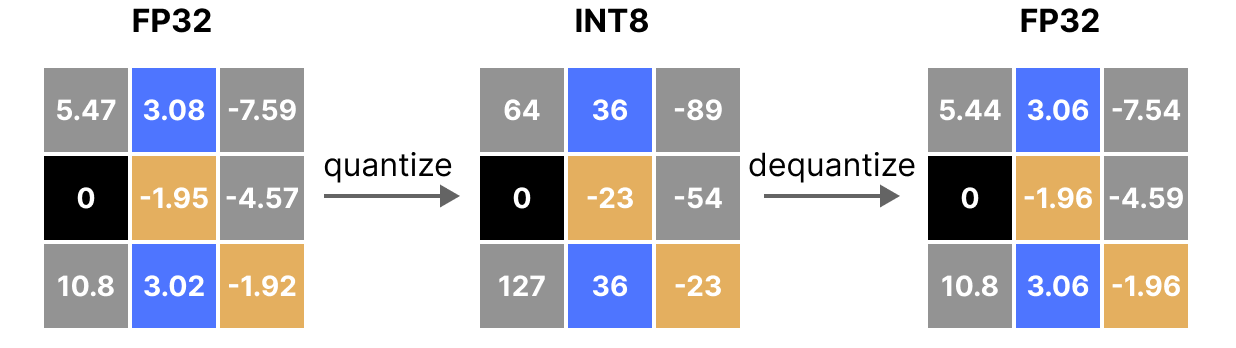
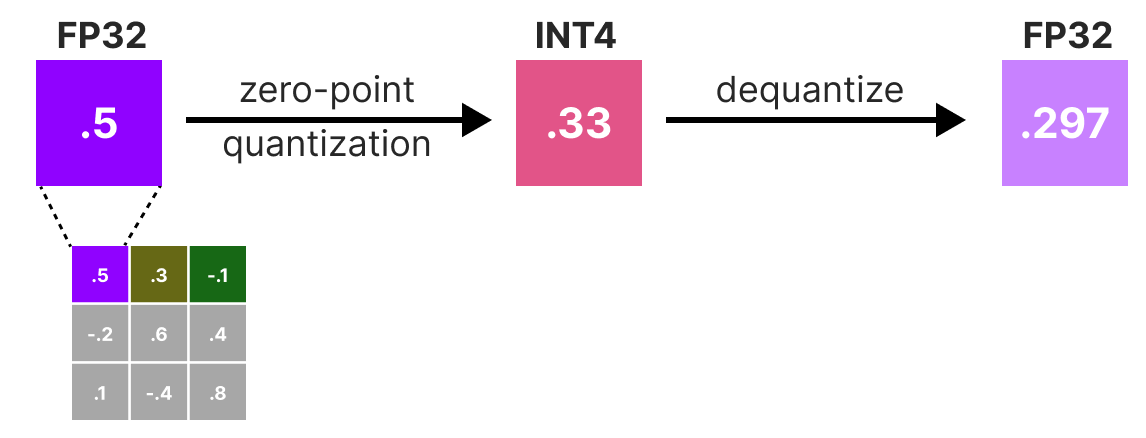
A Visual Guide to Quantization - by Maarten Grootendorst
FlexQ: Efficient Post-training INT6 Quantization for LLM Serving via ...
Accelerating Triton Dequantization Kernels for GPTQ – PyTorch
A Visual Guide to Quantization - Maarten Grootendorst
Understanding Int4 scalar quantization in Lucene - Search Labs
Full Integer Quantization. | Download Scientific Diagram
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
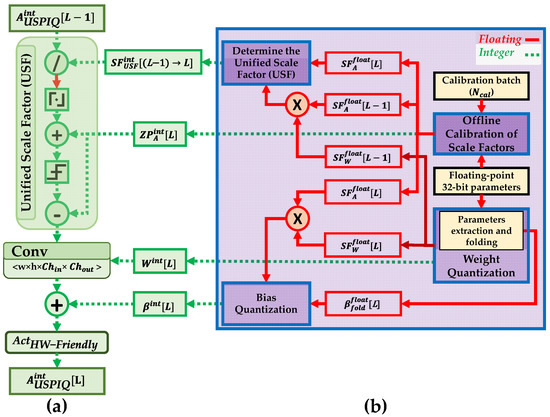
The flow diagram of the Unified Scaling-Based Pure-Integer Quantization ...
How Quantization Works & Quantizing SAM
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
INT8 Quantization for x86 CPU in PyTorch | PyTorch
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
GitHub - xuanandsix/Tensorrt-int8-quantization-pipline: a simple ...
INT8, INT4 and Other Integer Types for Quantization
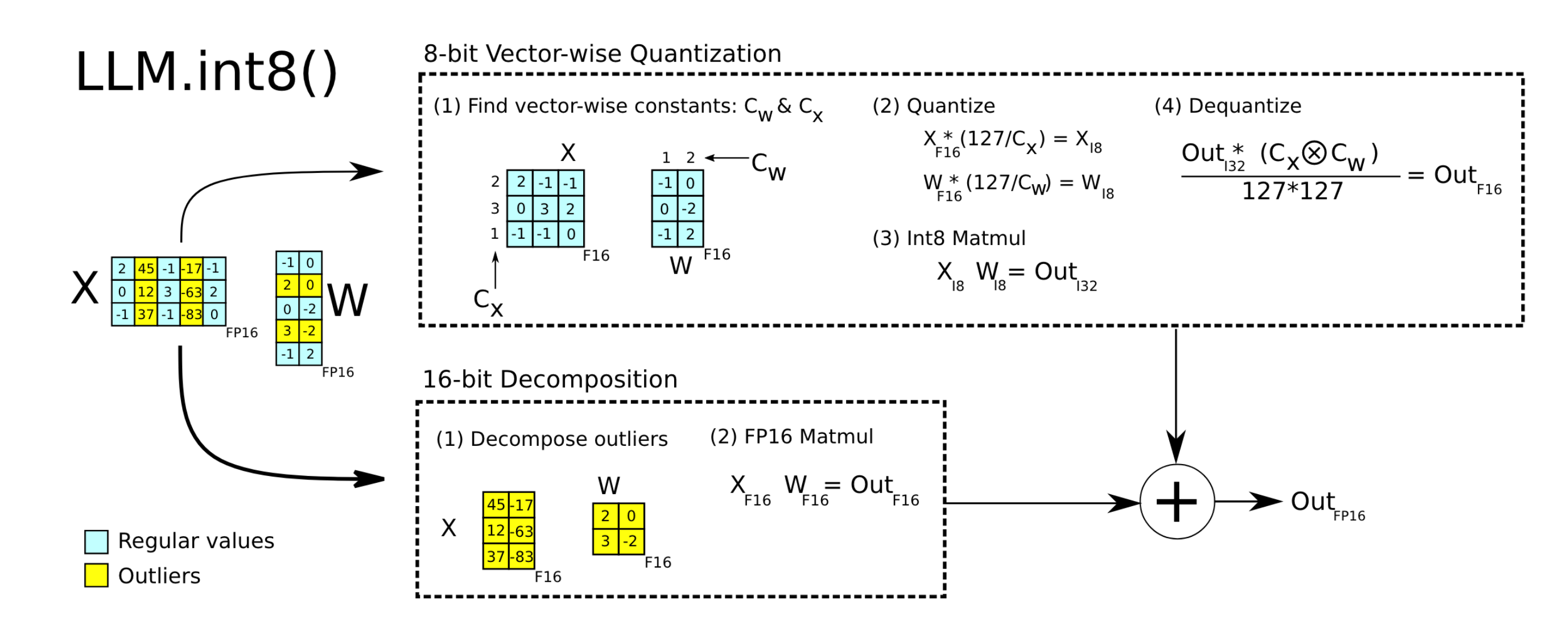
Understanding LLM.int8() Quantization — Picovoice
The framework of Variable Integer-based Quantization method for ANN ...
Unified Scaling-Based Pure-Integer Quantization for Low-Power ...
What Is A Quantizer at Tyson Macgillivray blog
Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
INT8 Quantization Basics | Rand Xie
How to optimize large deep learning models using quantization
[2307.09782] ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 ...
模型量化(Model Quantization)-CSDN博客
INT4 Quantization (with code demonstration)
Deep Learning Int8 Quantization – PCETSK
PPT - Vertex Shaders for Geometry Compression: Techniques and ...
Integer quantization for deep learning inference: principles and ...
The accuracy loss after INT8 quantization compared to FP16 version ...
How Quantization Works: From a Matrix Multiplication Perspective ...
The Quantization Horizon: Navigating the Transition to INT4, FP4, and ...
Google Colab
PPT - Understanding Digital Images: Creation through Sampling and ...
#1 - Getting Started - No BS Intro To Developing with LLMs | GDCorner
The impact of INT8 quantization on throughput. | Download Scientific ...
Quantization: A Crucial Technique in Today’s AI Landscape | The AI Noob
A Survey On Neural Network Quantization | Proceedings of the 2025 6th ...
INT8 quantization with Benchmark Studio
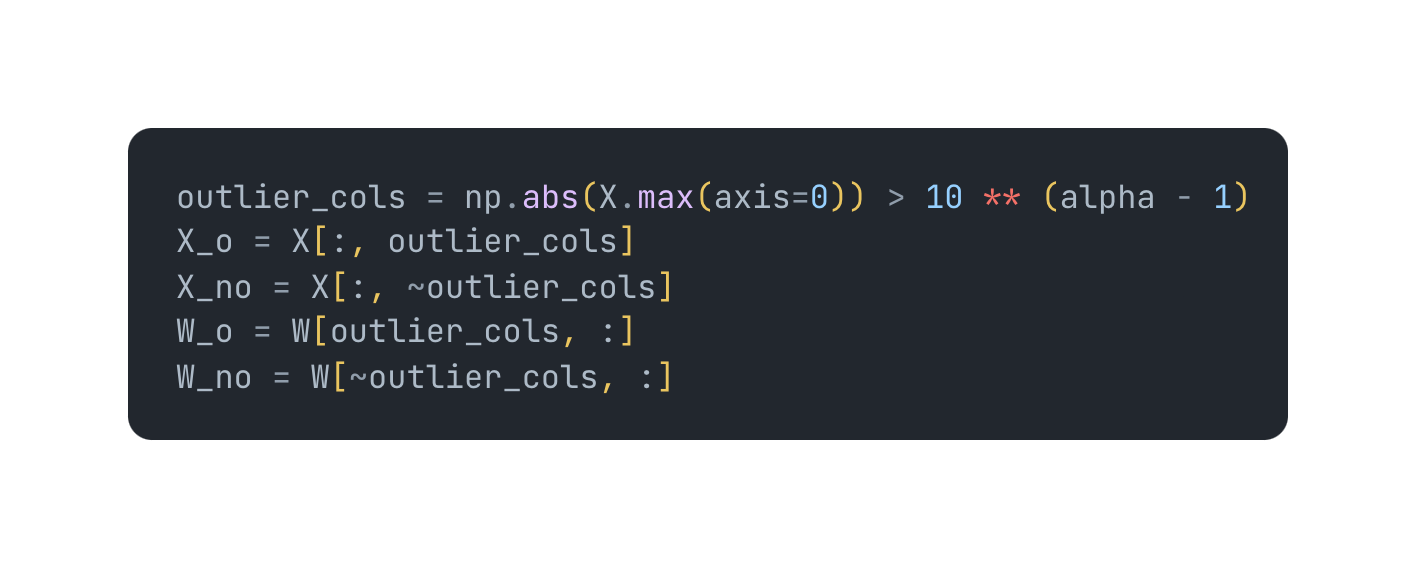
MicroScopiQ: Accelerating Foundational Models through Outlier-Aware ...
Three Big Stages in Machine Learning Pipeline Collection
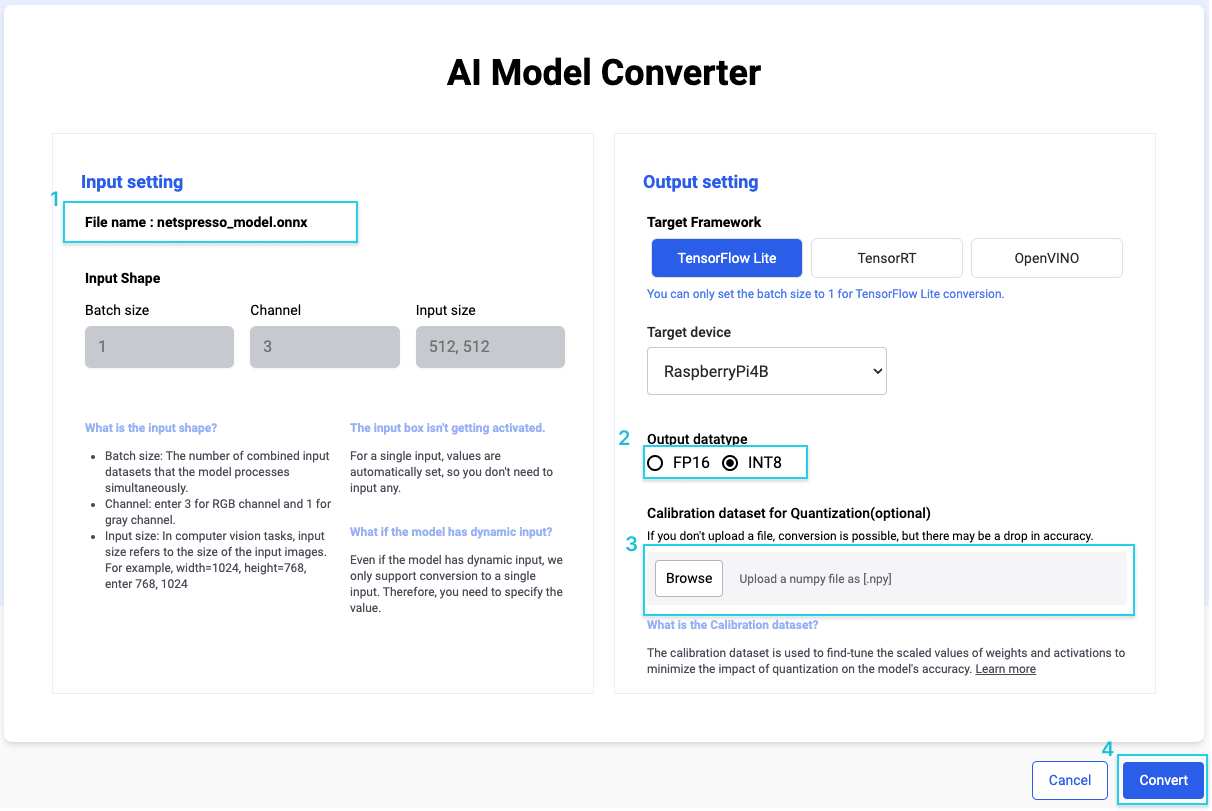
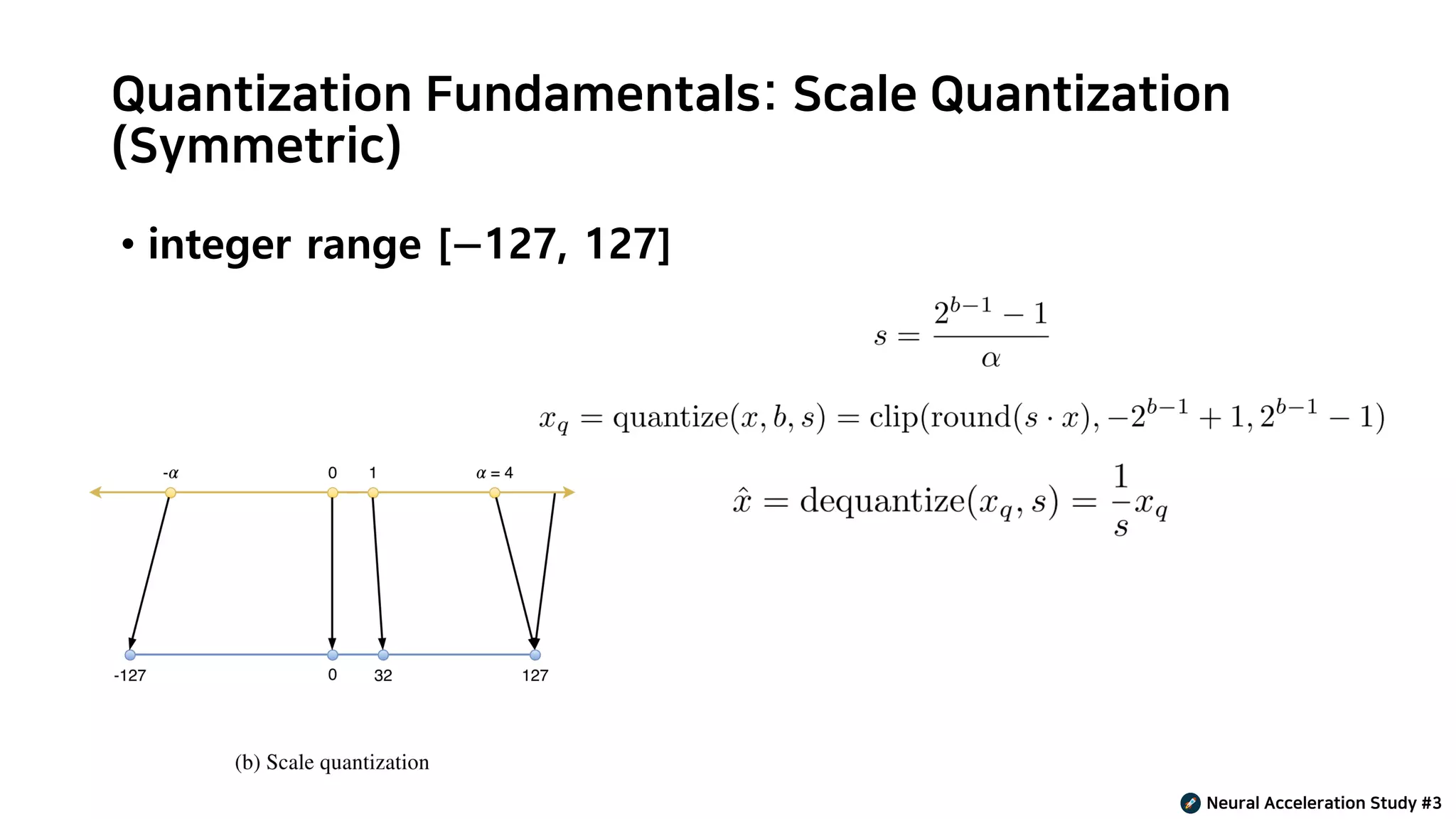
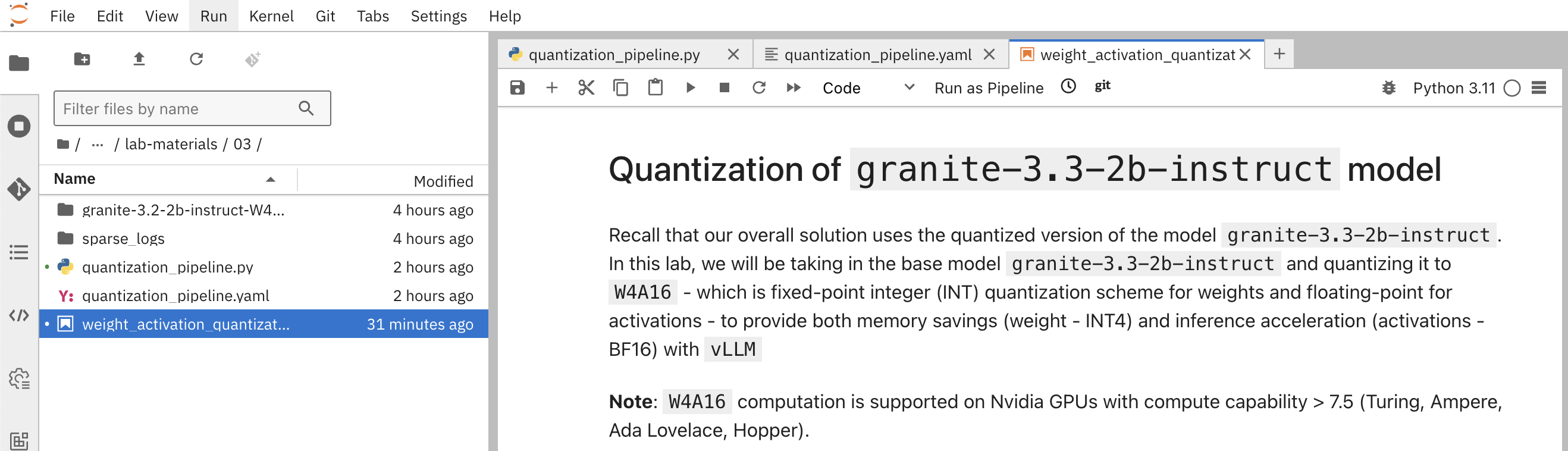
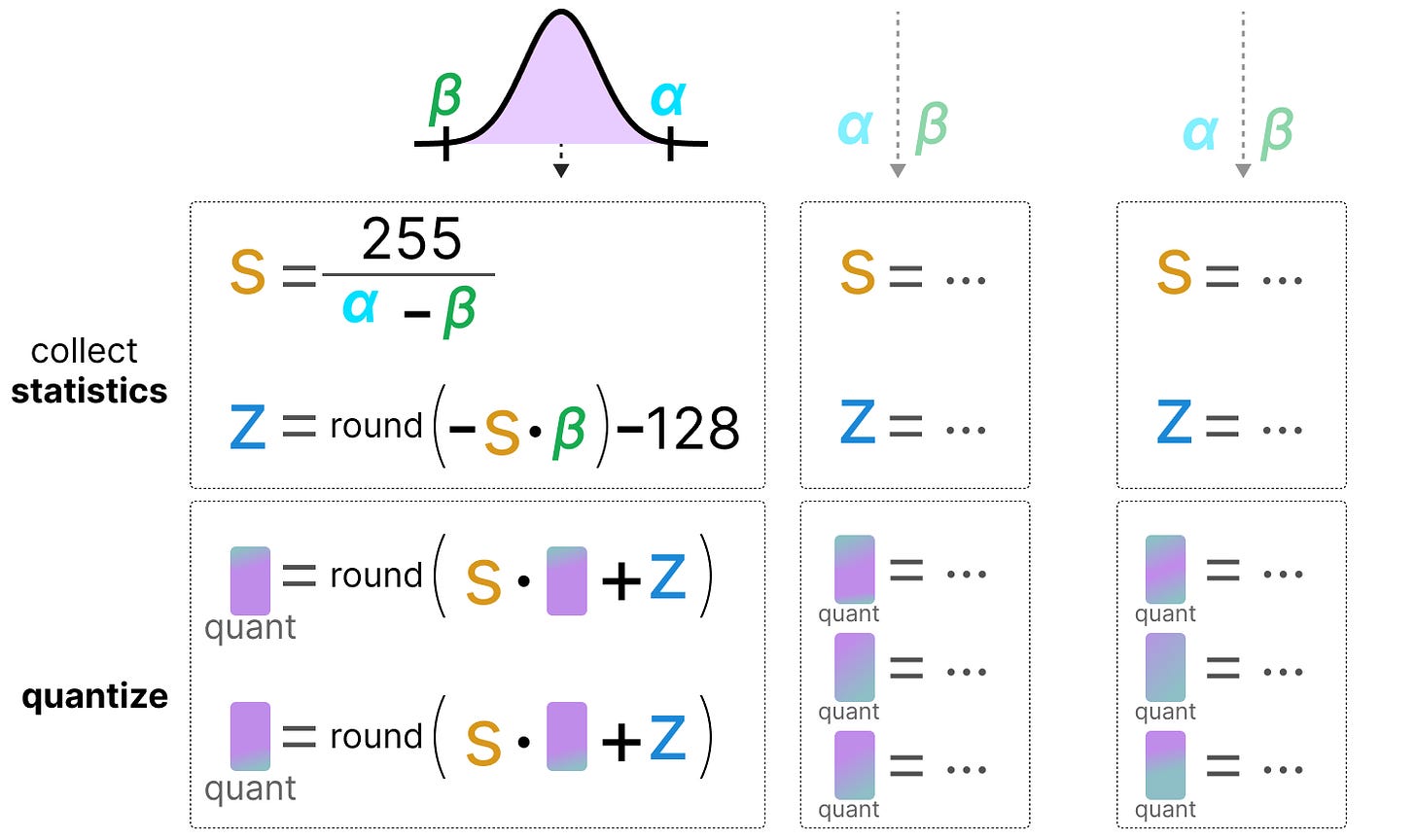
Weights and Activation Quantization (W4A16) :: LLM optimization and ...
Quantization for Neural Networks | Yang Yang
Introduction to Quantization
Quantization: Reducing Model Precision (FP16, INT8)
int8 Weight and Activation Quantization - LLM Compressor Docs
A Contrast between INT8 and FP8 Quantization Methods. The top row ...
Optimizing Neural Networks: Unveiling the Power of Quantization
Experimental results of our int8 quantization and other previous ...
High level overview of INT-FP-QSim. The user specifies the input model ...
quantizer - Create quantizer object - MATLAB
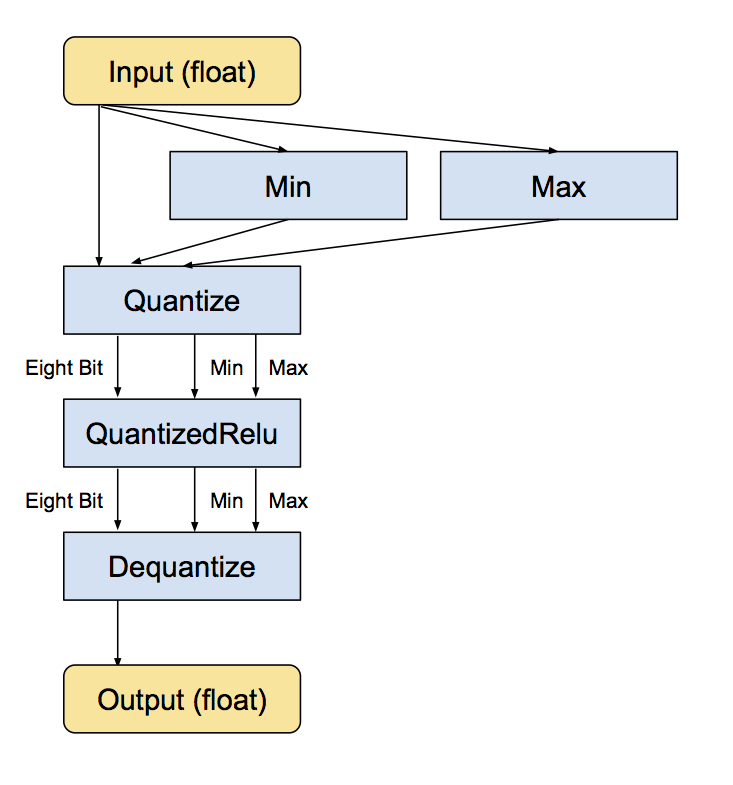
What is Quantization and how to use it with TensorFlow
A Survey of Quantization Methods for Efficient Neural Network Inference ...
Local Large Language Models | Int8
Quantization from FP32 to INT8. | Download Scientific Diagram
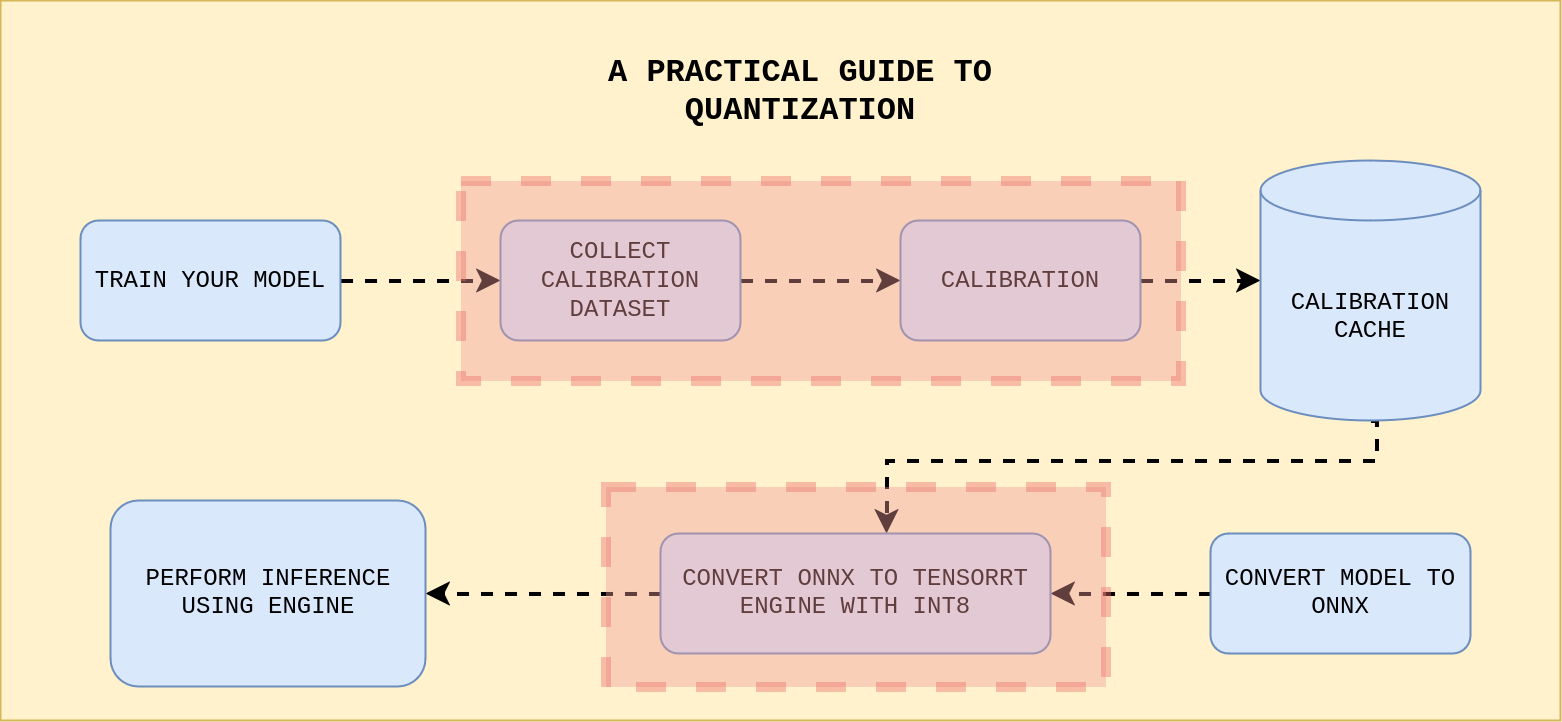
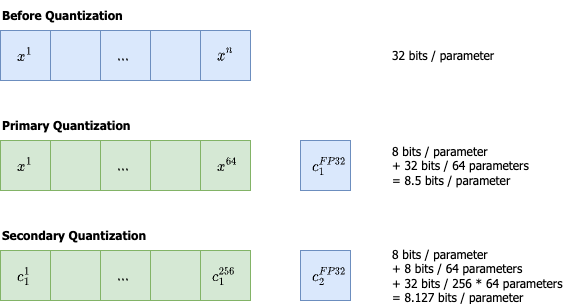
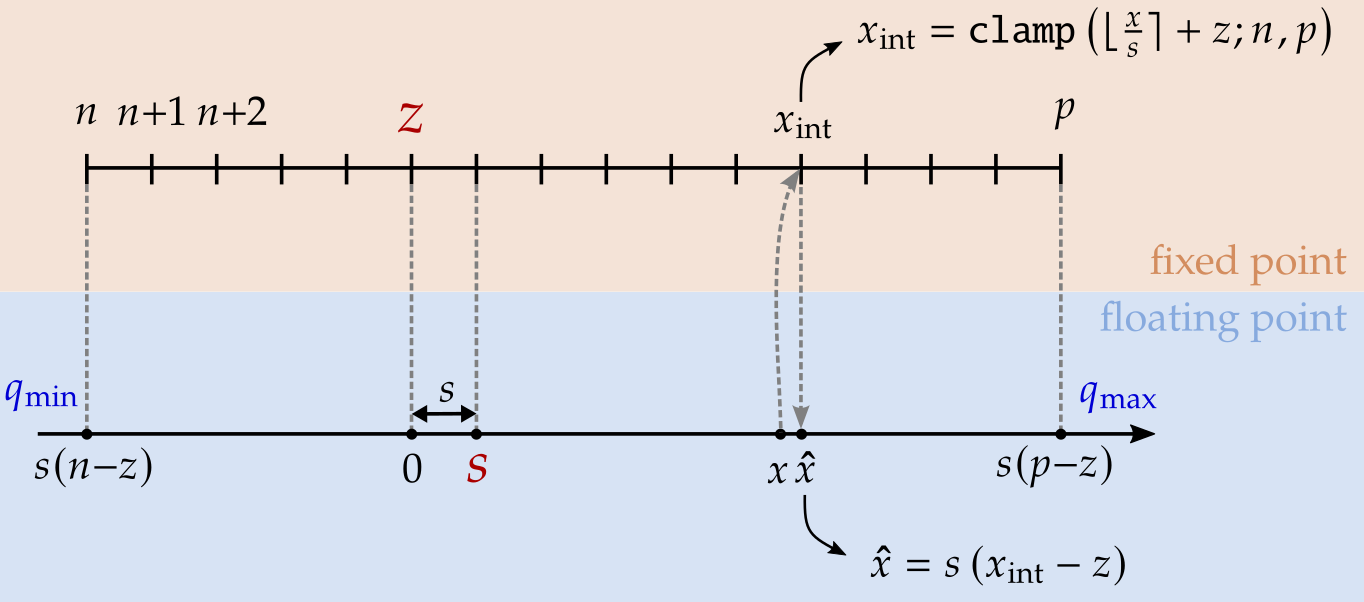
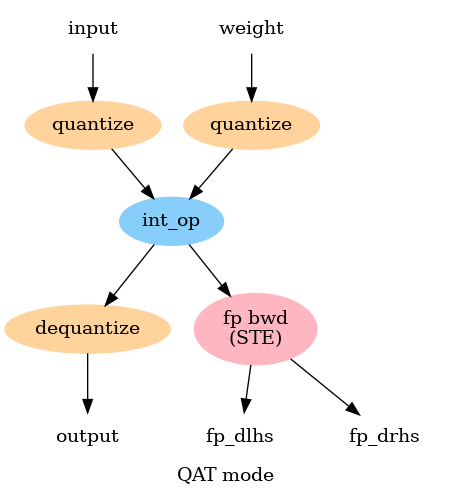
A practical guide to Quantization | Sanket Shah
Quantization in LLMs: Why Does It Matter?
Training with Quantization (QAT/QT) — qwix documentation
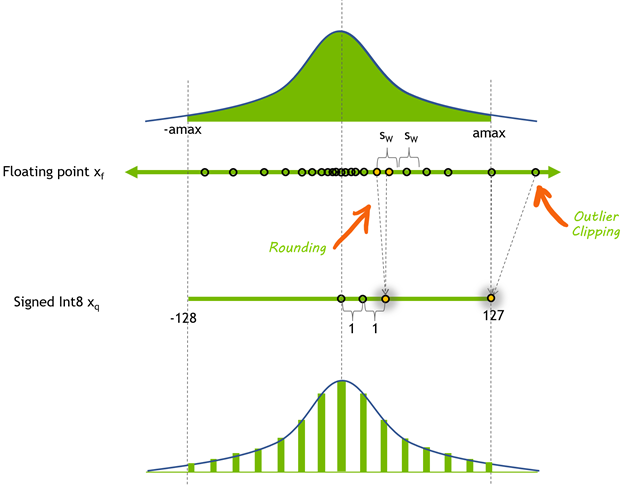
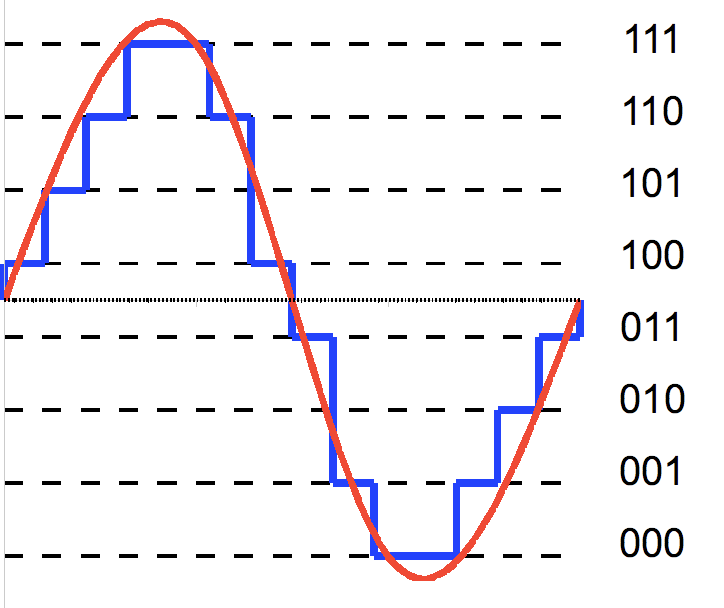
Rounding towards zero (Int); mid-tread quantization with double ...
Fast and Accurate GPU Quantization for Transformers
Integer-arithmetic-only quantization | Download Scientific Diagram
Quantization
Quantization คืออะไร Post-Training Quantization มีประโยชน์อย่างไร กับ ...